

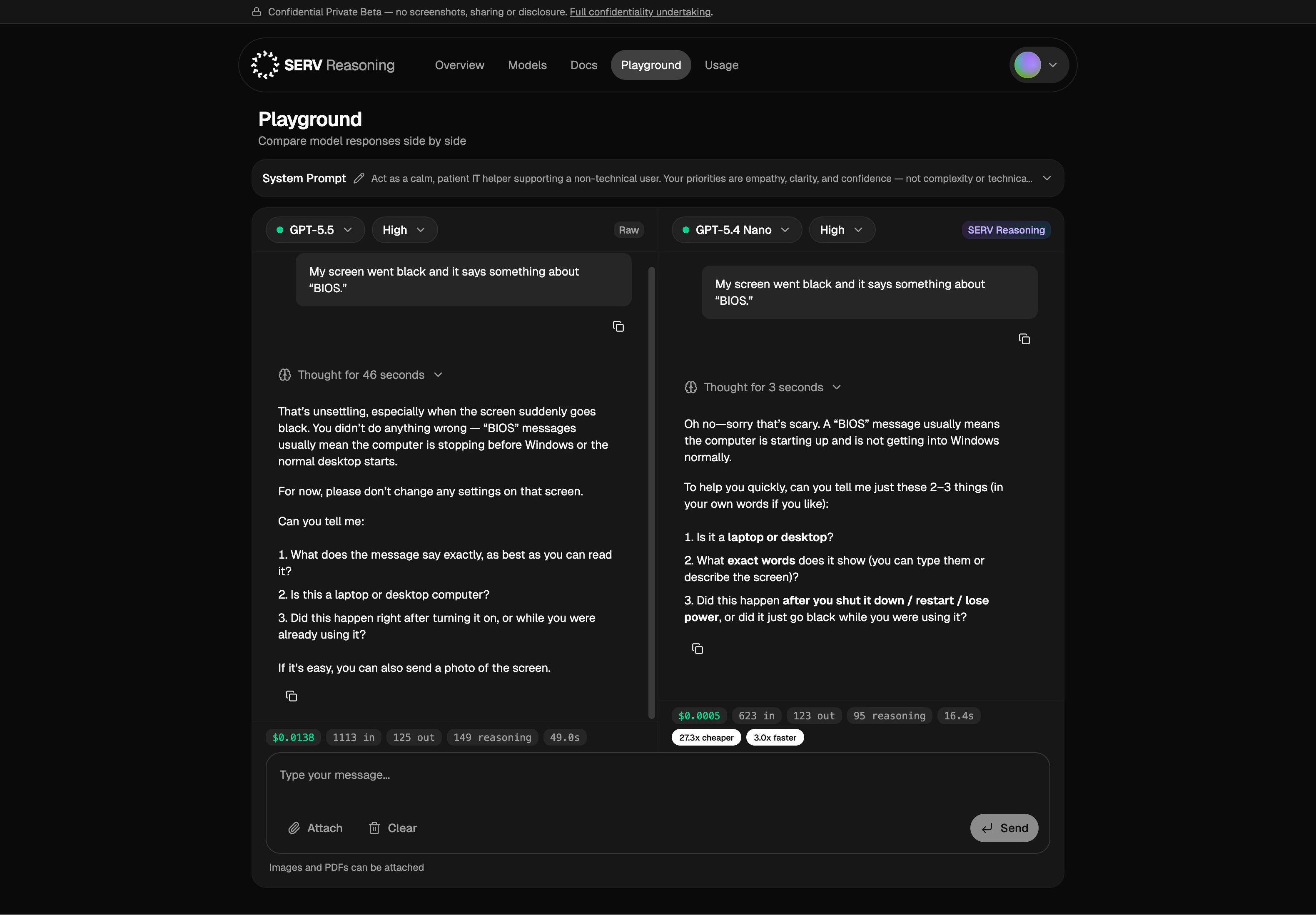
What you can do
- Compare models side by side. Run the same prompt through any two models — one with SERV Reasoning, one without.
- See cost, tokens, and latency. Each side shows real metrics for the response.
- Iterate on your system prompt. Edit it at the top and rerun before baking anything in.
- Bring your own prompts. Start from the samples, then paste in your real workload.